2023年10月11日,第九届HAOMO AI DAY盛大开幕。本次HAOMO AI DAY以“BETTER AI,BETTER HAOMO”为主题,内容丰富,既有业内专家的精彩讲座和尖端技术的展览,同时也设有多个活泼有趣的活动和互动环节,使参与者深刻体验到了自动驾驶技术的吸引力和可能性。
历届HAOMO AI DAY的核心主题都是聚焦最硬核的自动驾驶AI技术。此次,毫末智行CEO顾维灏带来了主题为《自动驾驶3.0时代:大模型将重塑汽车智能化的技术路线》的演讲,分享了毫末对于自动驾驶3.0时代AI开发模式的思考以及自动驾驶生成式大模型毫末DriveGPT大模型的最新进展和实践。

(毫末智行CEO顾维灏)
顾维灏认为,自动驾驶3.0时代与2.0时代相比,其开发模式和技术框架都将发生颠覆性的变革。在自动驾驶2.0时代,以小数据、小模型为特征,以Case任务驱动为开发模式。而自动驾驶3.0时代,以大数据、大模型为特征,以数据驱动为开发模式。

(毫末提出的自动驾驶3.0时代的技术架构演进趋势)
相比2.0时代主要采用传统模块化框架,3.0时代的技术框架会发生颠覆性变化。首先,自动驾驶会在云端实现感知大模型和认知大模型的能力突破,并将车端各类小模型逐步统一为感知模型和认知模型,同时将控制模块也AI模型化。随后,车端智驾系统的演进路线也是一方面会逐步全链路模型化,另一方面是逐步大模型化,即小模型逐渐统一到大模型内。然后,云端大模型也可以通过剪枝、蒸馏等方式逐步提升车端的感知能力,甚至在通讯环境比较好的地方,大模型甚至可以通过车云协同的方式实现远程控车。最后,在未来车端、云端都是端到端的自动驾驶大模型。
顾维灏还详细介绍了毫末DriveGPT大模型在推出200天后的整体进展。首先是DriveGPT训练数据规模提升。截至2023年10月DriveGPT雪湖·海若共计筛选出超过100亿帧互联网图片数据集和480万段包含人驾行为的自动驾驶4D Clips数据。其次是通用感知能力提升,DriveGPT通过引入多模态大模型,实现文、图、视频多模态信息的整合,获得识别万物的能力;同时,通过与NeRF技术整合,DriveGPT实现更强的4D空间重建能力,获得对三维空间和时序的全面建模能力;最后是通用认知能力提升,借助大语言模型,DriveGPT将世界知识引入到驾驶策略中。
顾维灏认为,未来的自动驾驶系统一定是跟人类驾驶员一样,不但具备对三维空间的精确感知测量能力,而且能够像人类一样理解万物之间的联系、事件发生的逻辑和背后的常识,并且能基于这些人类社会的经验来做出更好的驾驶策略,真正实现完全无人驾驶。
毫末DriveGPT是如何具备识别万物的他通用感知能力,以及拥有世界知识的通用认知能力?顾维灏也给出了详尽解释。

(毫末DriveGPT升级:大模型让自动驾驶拥有世界知识)
在感知阶段,DriveGPT首先通过构建视觉感知大模型来实现对真实物理世界的学习,将真实世界建模到三维空间,再加上时序形成4D向量空间;然后,在构建对真实物理世界的4D感知基础上,毫末进一步引入开源的视觉文本多模态大模型,构建更为通用的语义感知大模型,实现文、图、视频多模态信息的整合,从而完成4D向量空间到语义空间的对齐,实现跟人类一样的“识别万物”的能力。
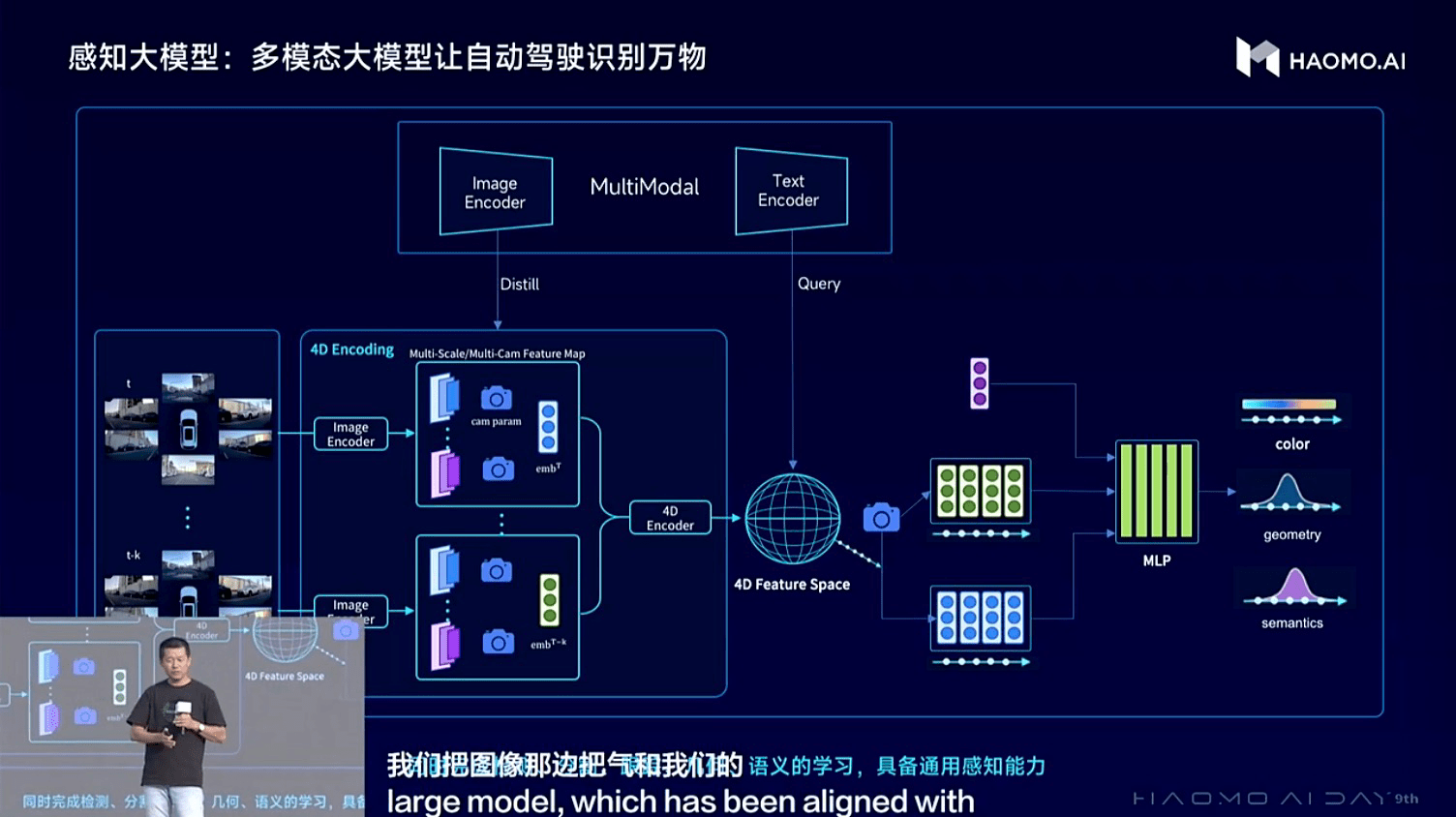
(毫末DriveGPT通用感知大模型:让自动驾驶认识万物)
毫末通用感知能力的进化升级包含两个方面。首先是视觉大模型的CV Backbone的持续进化,当前基于大规模数据的自监督学习训练范式,采用Transformer大模型架构,实现视频生成的方式来进行训练,构建包含三维的几何结构、图片纹理、时序信息等信息的4D表征空间,实现对全面的物理世界的感知和预测。其次是构建起更基础的通用语义感知大模型,在视觉大模型基础上引入视觉文本多模态模型来提升感知效果,视觉文本多模态模型可以对齐自然语言信息和图片的视觉信息,在自动驾驶场景中就可以对齐视觉和语言的特征空间,从而具备识别万物的能力,也由此可以更好完成目标检测、目标跟踪、深度预测等各类任务。
在认知阶段,基于通用语义感知大模型提供的“万物识别”能力,DriveGPT通过构建驾驶语言(Drive Language)来描述驾驶环境和驾驶意图,再结合导航引导信息以及自车历史动作,并借助外部大语言模型LLM的海量知识来辅助给出驾驶决策。
由于大语言模型已经学习到并压缩了人类社会的全部知识,因而也就包含了驾驶相关的知识。经过毫末对大语言模型的专门训练和微调,从而让大语言模型更好地适配自动驾驶任务,使得大语言模型能真正看懂驾驶环境、解释驾驶行为,做出驾驶决策。认知大模型通过与大语言模型结合,使得自动驾驶认知决策获得了人类社会的常识和推理能力,也就是获得了世界知识,从而提升自动驾驶策略的可解释性和泛化性。

(毫末DriveGPT应用的七大实践)
在分享了最新DriveGPT大模型技术框架后,顾维灏随后也给出了毫末基于DriveGPT大模型开发模式的七大应用实践,包括驾驶场景理解、驾驶场景标注、驾驶场景生成、驾驶场景迁移、驾驶行为解释、驾驶环境预测和车端模型开发。
其中,在驾驶行为解释方面,毫末DriveGPT在原有结合场景库及人工标注方式来对驾驶行为进行解释的基础上,升级为引入大语言模型来解释驾驶环境,让AI自己解释自己的驾驶决策。接下来,毫末会持续通过构建自动驾驶描述数据,来对大语言模型进行微调,让大语言模型能够像驾校教练或者陪练一样,对驾驶行为做出更详细的解释。

(驾驶行为解释:透视AI的思考过程)
驾驶环境预测方面,毫末DriveGPT原来基于海量人驾数据预训练和接管数据的反馈强化学习来完成未来BEV场景的预测生成,现在则是通过引入大语言模型,在使用驾驶行为数据的同时,让大语言模型对当前的驾驶环境给出解释和驾驶建议,然后再将驾驶解释和驾驶建议作为prompt输入到生成式大模型,来让自动驾驶大模型获得外部大语言模型内的人类知识,从而具备常识,才能理解人类社会的各种明规则、潜规则,才能跟老司机一样,预测未来最有可能出现的驾驶场景,从而与各类障碍物进行更好地交互。

(驾驶环境预测:生成未来世界)
车端模型开发模式变革方面,毫末正在尝试用蒸馏的方法,也就是用大模型输出的伪标签作为监督信号,让车端小模型来学习云端大模型的预测结果,或者通过对齐Feature Map的方式,让车端小模型直接学习并对齐云端的Feature Map,从而提升车端小模型的能力。基于蒸馏的方式,可以让车端的感知效果提升五个百分点。
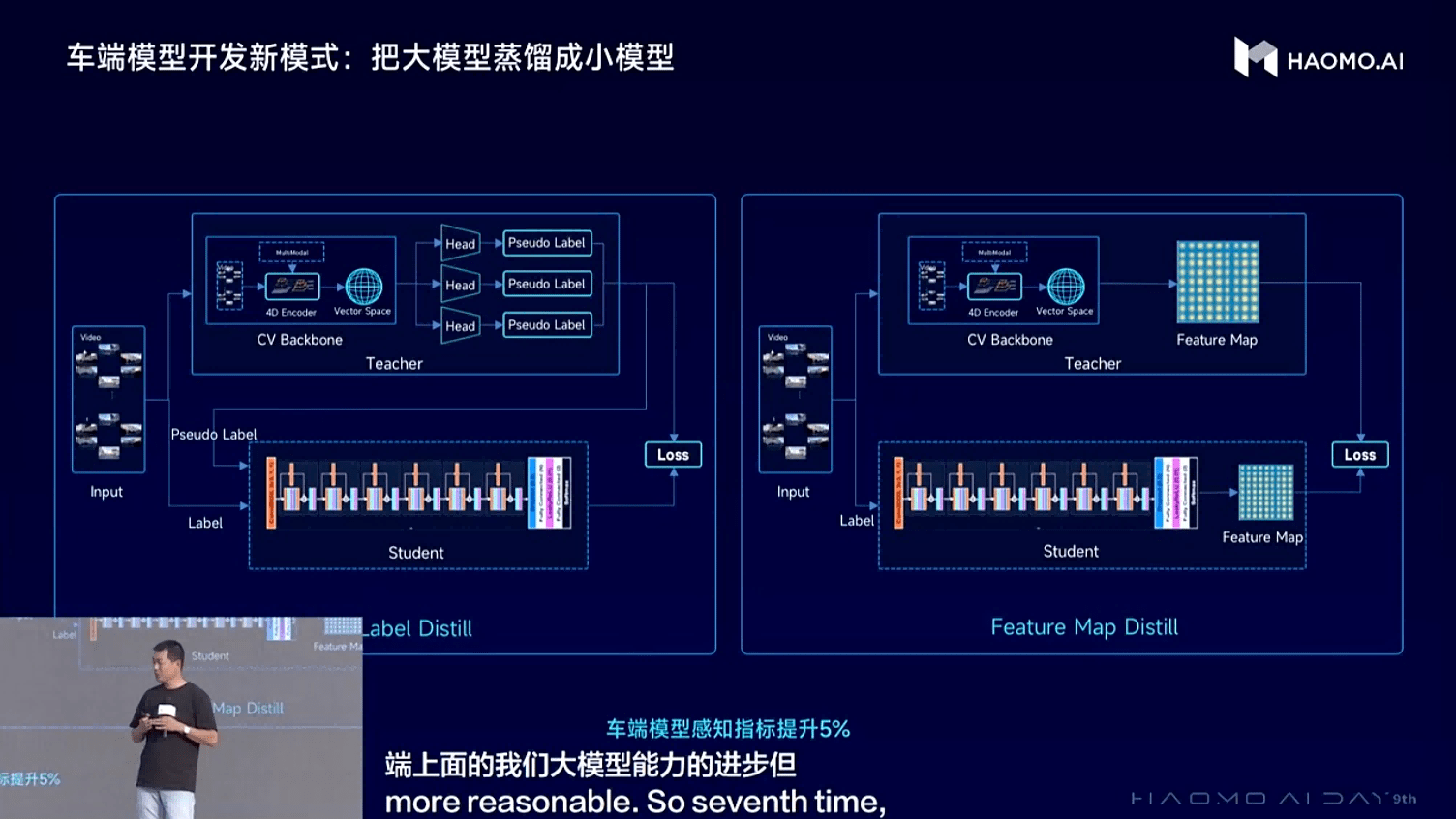
(车端模型开发新模式:把大模型蒸馏成小模型)
此外,毫末DriveGPT的驾驶场景理解可以对海量驾驶场景数据进行秒级特征搜索,从而实现更高效的数据筛选,为大模型挖掘海量高质量训练数据;驾驶场景标注是采用了开集(Open-set)场景下的Zero-Shot自动标注,可实现对任意物体既快速又精准的标注,不仅可实现针对新品类的Zero-Shot快速标注,而且精度还非常高,预标注准召达到80%以上;驾驶场景生成,可以基于驾驶场景的文生图模型,通过文字描述批量生成平时难以获取的Hardcase数据,实现无中生有的可控生成;对于驾驶场景迁移,基于AIGC生成能力,可实现多目标场景生成,能将采集到的一个场景,迁移到该场景的不同时间、不同天气、不同光照等各类新场景下,可同时获取全天候驾驶数据,实现瞬息万变的高效场景迁移。
现场,顾维灏还给出了DriveGPT赋能车端的三大测试成果:
第一个是毫末纯视觉自动泊车测试成果。毫末利用视觉感知模型,使用鱼眼相机可以识别墙、柱子、车辆等各类型的边界轮廓,形成360度的全视野动态感知,可以做到在15米范围内达到30cm的测量精度,2米内精度可以高于10cm。这样的精度可实现用视觉取代USS,从而进一步降低整体智驾方案成本。

(毫末纯视觉泊车)
第二个是毫末对交通场景全要素识别测试成果。DriveGPT基于通用感知的万物识别的能力,从原有感知模型只能识别少数几类障碍物和车道线,到现在可以识别各类交通标志、地面箭头,甚至井盖等交通场景的全要素数据。大量高质量的道路场景全要素标注数据,可以有效帮助毫末重感知的车端感知模型实现效果的提升,助力城市NOH的加速进城。
第三个是毫末城市NOH对小目标障碍物检测的测试成果。毫末在当前城市NOH的测试中,可以在城市道路场景中,在时速最高70公里的50米距离外,就能检测到大概高度为35cm的小目标障碍物,可以做到100%的成功绕障或刹停,这样可以对道路上穿行的小动物等移动障碍物起到很好地检测保护作用。
据顾维灏透露,DriveGPT的云端能力也对外开放,合作伙伴可以通过使用API、模型的专项优化、服务的私有化部署,与毫末合作。DriveGPT发布200天左右的时间里,累积480万段Clips高质量测试。目前已有生态伙伴17家,助力生态伙伴提效90%。2023年DriveGPT成功入选“北京市通用人工智能产业创新伙伴计划”成为首批模型伙伴观察员及入选北京市首批人工智能10个行业大模型应用案例。此外,DriveGPT还助力毫末荣获2023中国AI基础大模型创新企业的称号。
顾维灏也提到,毫末DriveGPT大模型的应用,在自动驾驶系统开发过程中带来了巨大技术提升,使得毫末的自动驾驶系统开发彻底进入了全新模式,新开发模式和技术架构将大大加速汽车智能化的进化进程。
免责声明:本文转自网络,仅代表作者个人观点,与亚讯车网无关。其原创性以及文中陈述文字和内容(包括图片版权等问题)未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。
编辑:亚讯编辑部
关键词:模型,驾驶,DriveGPT,场景,自动

 小米汽车官方回答SU7安徽事故疑问
小米汽车官方回答SU7安徽事故疑问
 雷军对安徽小米SU7事故:无论发生什么,小米不会回避
雷军对安徽小米SU7事故:无论发生什么,小米不会回避
 蔚来能源:7000万次换电成就正式达成
蔚来能源:7000万次换电成就正式达成
 碰撞车速97km/h 小米公布“碰撞爆燃”事故车辆信息
碰撞车速97km/h 小米公布“碰撞爆燃”事故车辆信息
 小米汽车:“有信心达成35万台全年交付目标”
小米汽车:“有信心达成35万台全年交付目标”
 从水立方到全国街头,九号公司携手车友,共同守护孤独症群体的成长与未来
从水立方到全国街头,九号公司携手车友,共同守护孤独症群体的成长与未来
 值得期待 2023天津车展将于9月28日开幕
值得期待 2023天津车展将于9月28日开幕
 将亮相慕尼黑车展 零跑全新SUV代号B11
将亮相慕尼黑车展 零跑全新SUV代号B11
 领克公布:智能座舱操作系统升级计划
领克公布:智能座舱操作系统升级计划